K8s 的 HPA (Horizontal Pod Autoscaler) 自动扩缩容在 kube-controller-manager 中的 HPA Controller 中实现,它通过 APIServer 的 *metrics.k8s.io APISerice 访问 各种 metrics 提供者,其中基础 CPU 内存 的 resource metrics 由 metrics-server 组件提供,它会定时查询各个节点 kubelet 缩暴露的容器监控数据并保存到内存中以供获取,除 HPA 外,kubectl top 命令也依赖它。
HPA 架构图如下:
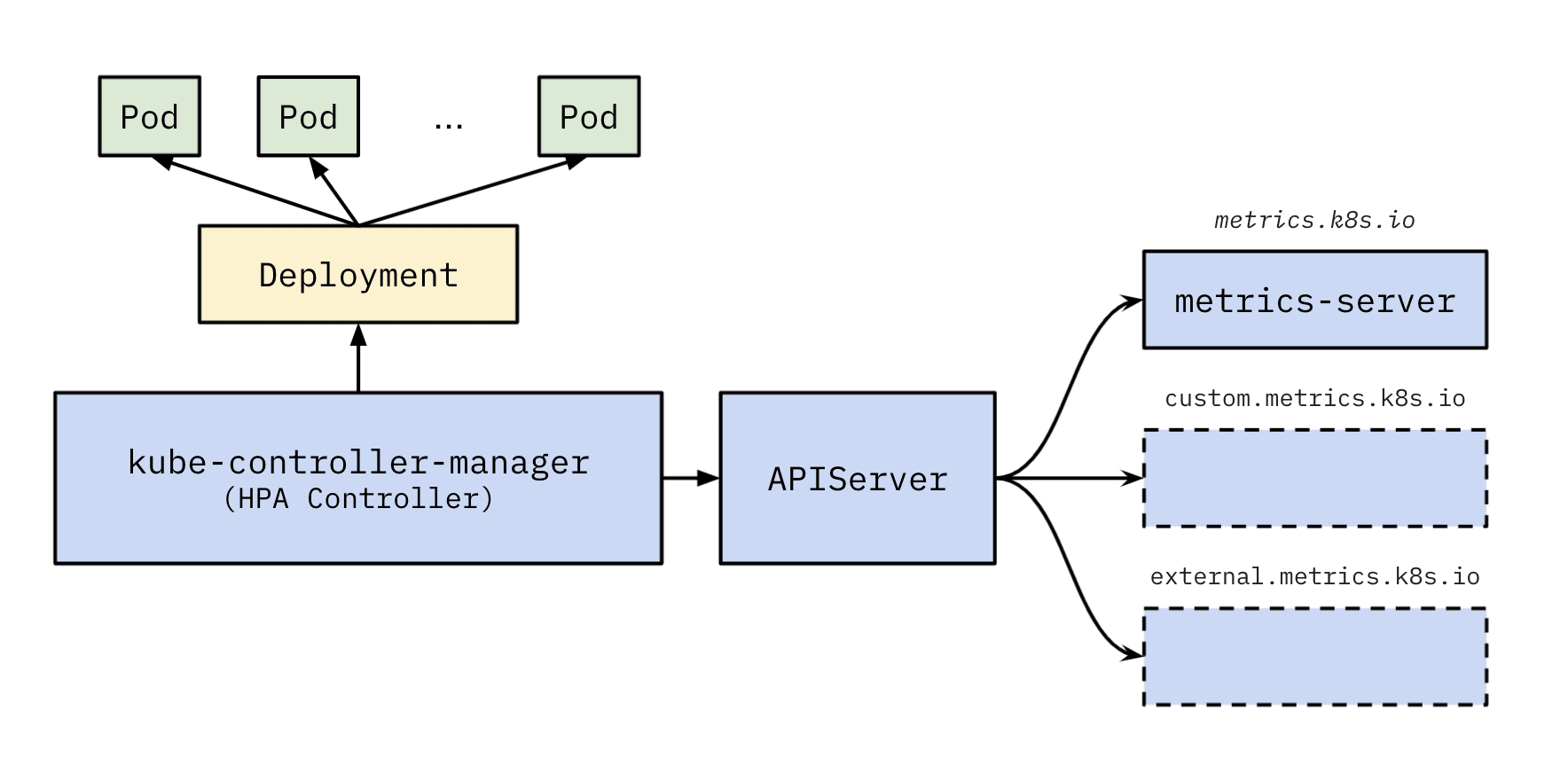
NewHorizontalController
HPA Controller 使用的 informer 有两个
hpaInformerpodInformer
其中 hpaInformer 有 EventHandler,用于监听 HPA 变化定时抓取 metrics 计算预期的实例数量,podInformer 仅用于 list
Run
和其他 Controller 无异,启动 worker 并从 workqueue 中取出任务执行,但对于 HPA Controller,有两点不同之处
- 启动的 worker 只有一个
- workqueue 是一个固定时间参数(默认 15s,也就是 HPA 的评估评率)的限速队列,以实现类似 Ticker 定时执行的效果
worker 工作逻辑
func (a *HorizontalController) processNextWorkItem() bool {
key, quit := a.queue.Get()
if quit {
return false
}
defer a.queue.Done(key)
deleted, err := a.reconcileKey(key.(string))
if err != nil {
utilruntime.HandleError(err)
}
// 周期性对 HPA 进行扩缩容判断的实现,processNextWorkItem 每处理完一个 HPA 对象
// 若此对象未被删除,则继续添加到 RateLimited 队列中等待下一次执行
if !deleted {
a.queue.AddRateLimited(key)
}
return true
}从队列中取得一个 HPA 对象在方法 reconcileKey 中评估执行扩缩容,返回了一个 delete 表示该 HPA 对象是否被删除,若未被删除则处理完后继续添加到这个 rateLimit 队列中,等待下一个时间周期到来后取出再次执行。
如何计算 HPA 推荐的实例数量
整体判断逻辑主要有四步
- 实例数量为 0 时不进行判断,禁用自动扩缩容,因此原生 HPA 不适用于 Scale From Zero
- 实例数量大于 max 时,缩容到上限
- 实例数量小于 min 时,扩容到下限
- 通过 HPA 指定的 Metrics 计算期望实例数量
// 1. 当前实例数量为 0,但是 HPA min 不为零时,禁用此 HPA 停止自动扩缩容
if scale.Spec.Replicas == 0 && minReplicas != 0 {
// Autoscaling is disabled for this resource
desiredReplicas = 0
rescale = false
} else if currentReplicas > hpa.Spec.MaxReplicas {
// 2. 当前实例数量大于 HPA max 时,缩容到上限
desiredReplicas = hpa.Spec.MaxReplicas
} else if currentReplicas < minReplicas {
// 3. 当前实例数量小于 HPA min 时,扩容到下限
desiredReplicas = minReplicas
} else {
var metricTimestamp time.Time
// 4. 通过指定的 metrics 计算出期望的实例数量 metricDesiredReplicas
// 但还并不是最终决定期望的数量,目前期望结果 desiredReplicas 还是 0
metricDesiredReplicas, metricName, metricStatuses, metricTimestamp, err = a.computeReplicasForMetrics(hpa, scale, hpa.Spec.Metrics)
//...
}通过 Metrics 计算期望实例数量时,会计算 HPA 中定义的所有 Metric 类型,并取出其中得到最高数量的实例数作为本次推荐值的计算结果:
for i, metricSpec := range metricSpecs {
replicaCountProposal, metricNameProposal, timestampProposal, condition, err := a.computeReplicasForMetric(hpa, metricSpec, specReplicas, statusReplicas, selector, &statuses[i])
if err != nil {
if invalidMetricsCount <= 0 {
invalidMetricCondition = condition
invalidMetricError = err
}
invalidMetricsCount++
}
// 取所有 metrics 结果的最大值
if err == nil && (replicas == 0 || replicaCountProposal > replicas) {
timestamp = timestampProposal
replicas = replicaCountProposal
metric = metricNameProposal
}
}缩容稳定窗口
HPA 在执行扩容时,若此次计算出的实例数量大于当前实例数,则会立即触发扩容,但缩容并不是低于当前实例数量就立即触发,为了避免 Pod 资源利用率的常规抖动而频繁进行扩缩容,可指定 downscaleStabilisationWindow 缩容稳定窗口 参数来进行稳定。具体原理是,每次评估完推荐值时不会直接使用此推荐值进行扩缩容操作,而是需要根据历史的推荐值记录重新评估一遍,保证此次使用的推荐实例数不会低于历史稳定窗口内任何一次历史推荐值,即取窗口内的历史最高值。
在 HPA Controller 使用一个 recommendations map 保存历史的扩缩容计算推荐值
recommendations map[string][]timestampedRecommendation
type timestampedRecommendation struct {
recommendation int32
timestamp time.Time
}实现稳定扩缩容的方法为 stabilizeRecommendation,主要有两个逻辑
- 判断稳定窗口内所有历史推荐值,取最大值作为本次的推荐
- 将稳定窗口前最旧的推荐值替换为计算出来最新的推荐值,轮转避免历史数据无限增长消耗内存
func (a *HorizontalController) stabilizeRecommendation(key string, prenormalizedDesiredReplicas int32) int32 {
maxRecommendation := prenormalizedDesiredReplicas
foundOldSample := false
oldSampleIndex := 0
cutoff := time.Now().Add(-a.downscaleStabilisationWindow)
for i, rec := range a.recommendations[key] {
if rec.timestamp.Before(cutoff) {
// 窗口时间之前的数据(旧数据)
foundOldSample = true
oldSampleIndex = i
} else if rec.recommendation > maxRecommendation {
// 窗口时间内的数据,每一个均需要判断是否比此次推荐数据大,若存在更大的则取历史中最大的那条
// max(currentRec, historyRec...)
maxRecommendation = rec.recommendation
}
}
if foundOldSample {
// 替换窗口外不需要的旧数据为最新一次的推荐值
a.recommendations[key][oldSampleIndex] = timestampedRecommendation{prenormalizedDesiredReplicas, time.Now()}
} else {
a.recommendations[key] = append(a.recommendations[key], timestampedRecommendation{prenormalizedDesiredReplicas, time.Now()})
}
return maxRecommendation
}两个参数
Pod 在其生命周期中随时可能会有各种状态的变化,以下两个参数决定了 Pod 哪些状态的 Pod 不会被纳入 HPA 的计算中
cpuInitializationPeriodDefault: 5m0s The period after pod start when CPU samples might be skipped.delayOfInitialReadinessStatusDefault: 30s The period after pod start during which readiness changes will be treated as initial readiness.
相关 PR:kubernetes/kubernetes#68068 中说明,忽略以下情况的 Pod
- Pod is beeing initalized - 5 minutes from start defined by flag
- Pod is unready
- Pod is ready but full window of metric hasn’t been colected since transition
- Pod is initialized - 5 minutes from start defined by flag:
- Pod has never been ready after initial readiness period.
但是其描述的说法并不太准确,通过阅读源码得知,cpuInitializationPeriod (5min) 参数将 Pod 生命周期分为两个时段来判断是否要纳入计算
Pod 启动前 5min
- 若 Pod 当前状态是 Unready 则直接视为 Unready
- 若 Pod 当前状态是 Ready 且其 ReadyCondition 变为 true 的时间已经超过
metric.Window(30s),才会被视为 Ready,即就算短时间内的探针通过也不算,必须要保证上次抓取到 metric 时该 Pod 也需要是 Ready 状态
Pod 启动 5min 后
这里则用到了 delayOfInitialReadinessStatus (30s) 参数,
- 若 Pod 当前状态是 Ready,直接视为 Ready 纳入计算
- 若 Pod 当前状态是 Unready ,且 ReadyCondition 上次变化的时间在 Pod 启动的 30s 之后,视为 Ready 都需要纳入 HPA 计算
- 若 Pod 当前状态是 Unready ,且 ReadyCondition 上次变化的时间在 Pod 启动的 30s 内,HPA 认为这个 Pod 从未 Ready 过,此情况视为 Unready 需要忽略掉
例如对于以下两个 Pod
- POD1: 10min 前启动、Unready、9min55(启动后 5s < 30s)前变为的 Unready,则视为 Unready => 忽略
- POD2: 10min 前启动、Unready、9min05(启动后 55s > 30s)前变为的 Unready,则视为 Ready => 不忽略
参考源码如下:
if resource == v1.ResourceCPU {
var unready bool
_, condition := podutil.GetPodCondition(&pod.Status, v1.PodReady)
if condition == nil || pod.Status.StartTime == nil {
unready = true
} else {
if pod.Status.StartTime.Add(cpuInitializationPeriod).After(time.Now()) {
// Pod 在启动前 cpuInitializationPeriod (默认5min) 内
// 若 Pod Unready 则忽略
// 若 Pod Ready,且在 metric.Window (默认30s) 时间内的 PodReady 状态变化也计为 Unready
unready = condition.Status == v1.ConditionFalse || metric.Timestamp.Before(condition.LastTransitionTime.Time.Add(metric.Window))
} else {
// Pod 在启动 cpuInitializationPeriod (默认5min) 后
// 当前 Unready,且是从启动后的 delayOfInitialReadinessStatus(默认30s) 内就 Unready 一直持续到现在,才忽略
// 即启动 5min 之后,对于 LastTransitionTime 在启动 30s 后变化的 Pod 不论现在是否是 ready 均视为 ready,要计入 HPA 计算中
unready = condition.Status == v1.ConditionFalse && pod.Status.StartTime.Add(delayOfInitialReadinessStatus).After(conditioLastTransitionTime.Time)
}
}
if unready {
unreadyPods.Insert(pod.Name)
continue
}
}