调度器结构
type Scheduler struct {
// It is expected that changes made via SchedulerCache will be observed
// by NodeLister and Algorithm.
SchedulerCache internalcache.Cache
Algorithm core.ScheduleAlgorithm
// PodConditionUpdater is used only in case of scheduling errors. If we succeed
// with scheduling, PodScheduled condition will be updated in apiserver in /bind
// handler so that binding and setting PodCondition it is atomic.
podConditionUpdater podConditionUpdater
// PodPreemptor is used to evict pods and update 'NominatedNode' field of
// the preemptor pod.
podPreemptor podPreemptor
// NextPod should be a function that blocks until the next pod
// is available. We don't use a channel for this, because scheduling
// a pod may take some amount of time and we don't want pods to get
// stale while they sit in a channel.
NextPod func() *framework.PodInfo
// Error is called if there is an error. It is passed the pod in
// question, and the error
Error func(*framework.PodInfo, error)
// Close this to shut down the scheduler.
StopEverything <-chan struct{}
// VolumeBinder handles PVC/PV binding for the pod.
VolumeBinder scheduling.SchedulerVolumeBinder
// Disable pod preemption or not.
DisablePreemption bool
// SchedulingQueue holds pods to be scheduled
SchedulingQueue internalqueue.SchedulingQueue
// Profiles are the scheduling profiles.
Profiles profile.Map
scheduledPodsHasSynced func() bool
}关键数据结构
SchedulingQueue 等待调度的 Pod 队列
调度队列是一个优先队列,其关键数据结构如下
type PriorityQueue struct {
// activeQ is heap structure that scheduler actively looks at to find pods to
// schedule. Head of heap is the highest priority pod.
activeQ *heap.Heap
// podBackoffQ is a heap ordered by backoff expiry. Pods which have completed backoff
// are popped from this heap before the scheduler looks at activeQ
podBackoffQ *heap.Heap
// unschedulableQ holds pods that have been tried and determined unschedulable.
unschedulableQ *UnschedulablePodsMap
// nominatedPods is a structures that stores pods which are nominated to run
// on nodes.
nominatedPods *nominatedPodMap
}共有三个结构用于保存不同状态的 Pod,Pending Pods 为以下三个队列数量之和
activeQ核心调度队列,要调度的 Pod 只会从这个队列 Pop 数据,数据结构为大根堆,堆顶部为优先级最高的 Pod,新创建的 Pod 会先加入到此队列podBackoffQunschedulableQ尝试过调度但是未能找到合适的节点的 Pod
backoff 队列和 unschedulable 队列有什么区别,不都是调度失败 Pod 保存的队列吗?如果有 move request 则进入 backoffQ 否则进入 unschedulableQ
启动 Run(ctx)
kube-scheduler 一旦获取 leader,便开始执行 Run 方法
func (sched *Scheduler) Run(ctx context.Context) {
if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) {
return
}
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}SchedulingQueue 调度队列
调度队列后台会启动两个 goroutine,分别将 podBackoffQ unschedulableQ 两个队列中的 Pod 根据是否满足条件重新移动到 activeQ 重新参与一次调度
func (p *PriorityQueue) Run() {
// 每秒从 backoff 队列中循环一遍所有 Pod
// 到达 backoff 时间的 Pod pop 出来加入到 activeQ 中
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
// 每 30s 从 unscheduableQ 中
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}集群有一些事件发生时会将 unscheduableQ 中的 Pod 全部放到 activeQ 或 backoffQ 中重新参与一遍调度,使用队列的 MoveAllToActiveOrBackoffQueue 方法,有如下事件会触发:
- Node 新增和更新
- PV、PVC 新增和更新
- Service 任何变化
- StorageClass 新增
- Pod 删除
如何决定一个未能成功调度的 Pod 放入到哪个队列中
// If a move request has been received, move it to the BackoffQ, otherwise move
// it to unschedulableQ.
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)
}
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", ScheduleAttemptFailure).Inc()
} else {
p.unschedulableQ.addOrUpdate(pInfo)
metrics.SchedulerQueueIncomingPods.WithLabelValues("unschedulable", ScheduleAttemptFailure).Inc()
}scheduleOne 调度一个 Pod
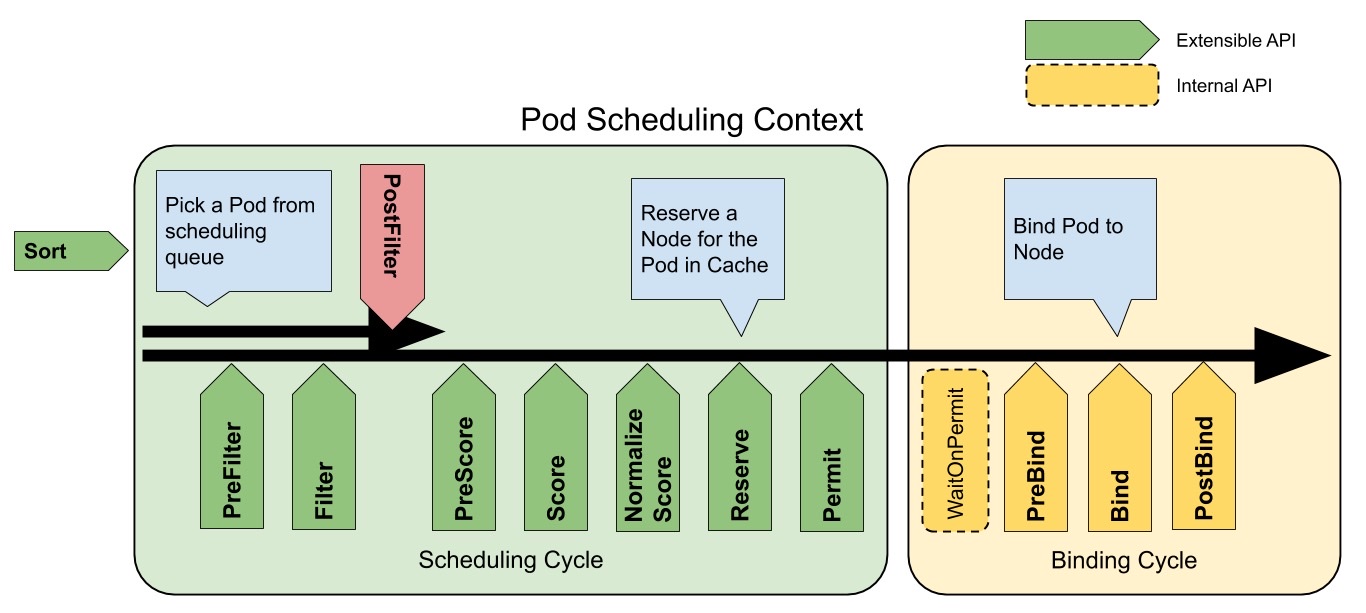
调度主要有两个步骤
- Filtering 筛选,筛选出一批满足要求的节点列表
- Scoring 打分,为每个节点打分选择最适合的节点,若多个相同最高分,则随机选择一个最高的
Pod 调度完整流程
-
从调度队列中 Pop 一个 Pod,若队列为空则阻塞
-
根据 Pod 获取该 Pod 指定调度器的 profile
-
调度 Schedule
sched.Algorithm.Schedule(ctx, prof, state, pod)上图绿色部分
-
snapshot node
-
RunPreFilterPlugins
-
开始 Predicate:
findNodesThatFitPod- 判断通过 framework 的 Filter: RunFilterPlugins,此处调度器启动了 16 个 worker 去对所有 node 并发 check 是否满足*
- 判断通过 extender 的 Filter
-
RunPreScorePlugins 打分前再次过滤一遍
-
打分
prioritizeNodes- 若没有配置打分插件则直接为所有节点设置为默认 1 分
- *RunScorePlugins* 并汇总所有打分结果
- 若有 extender 则并发调用 webhook 的 Prioritize
-
选择节点
selectHost-
选择节点源码,选择最高分者,若最高分相同则随机选择一个
func (g *genericScheduler) selectHost(nodeScoreList framework.NodeScoreList) (string, error) { if len(nodeScoreList) == 0 { return "", fmt.Errorf("empty priorityList") } maxScore := nodeScoreList[0].Score selected := nodeScoreList[0].Name cntOfMaxScore := 1 for _, ns := range nodeScoreList[1:] { if ns.Score > maxScore { maxScore = ns.Score selected = ns.Name cntOfMaxScore = 1 } else if ns.Score == maxScore { cntOfMaxScore++ if rand.Intn(cntOfMaxScore) == 0 { // Replace the candidate with probability of 1/cntOfMaxScore selected = ns.Name } } } return selected, nil }
-
-
至此,已经选择出一个唯一建议的调度节点
-
-
VolumeBind
sched.VolumeBinder.AssumePodVolumes -
RunReservePlugins
-
assume
-
RunPermitPlugins
-
异步 Bind,上图中的黄色部分
- WaitOnPermit 若失败则 RunUnreservePlugins
- RunPreBindPlugins
- RunBindPlugins
- RunPostBindPlugins
调度失败的处理
在整个调度周期中若调度错误,会调用 recordSchedulingFailure 方法记录失败的调度,其中主要做两个事
- 调用注册到 sched 中的 Error 方法
- 更新 Pod 的 Status 字段的 PodScheduled Condition 为 False
其中调度失败的处理逻辑 MakeDefaultErrorFunc 如下
- 判断错误类型并做出相应的后续处理:节点未找到时从调度 cache 中清除该节点,其他错误只是打印日志
- 再次重试:
- 重新获取 Pod 信息查看 nodeName 有没有被指定,若已经直接直接 return
- 重新获取 Pod 信息查看 Pod 是否还存在,若已经被删除则直接 return
- 若确实未被指定 node,则重新加入到调度队列中(podBackoffQ/unschedulableQ)
func MakeDefaultErrorFunc(client clientset.Interface, podQueue internalqueue.SchedulingQueue, schedulerCache internalcache.Cache) func(*framework.PodInfo, error) {
return func(podInfo *framework.PodInfo, err error) {
pod := podInfo.Pod
// 不同错误信息处理,不是特别关键,忽略
podSchedulingCycle := podQueue.SchedulingCycle()
// Retry asynchronously.
// Note that this is extremely rudimentary and we need a more real error handling path.
go func() {
defer utilruntime.HandleCrash()
podID := types.NamespacedName{
Namespace: pod.Namespace,
Name: pod.Name,
}
// An unschedulable pod will be placed in the unschedulable queue.
// This ensures that if the pod is nominated to run on a node,
// scheduler takes the pod into account when running predicates for the node.
// Get the pod again; it may have changed/been scheduled already.
// 启动一个独立 goroutine 去 backoff 重试加入到调度队列(不是重试调度)
// 初始 backoff 时间为 100ms,每次重试时间 *2,最大为 1min
getBackoff := initialGetBackoff
for {
pod, err := client.CoreV1().Pods(podID.Namespace).Get(context.TODO(), podID.Name, metav1.GetOptions{})
if err == nil {
if len(pod.Spec.NodeName) == 0 {
podInfo.Pod = pod
if err := podQueue.AddUnschedulableIfNotPresent(podInfo, podSchedulingCycle); err != nil {
klog.Error(err)
}
}
break
}
if apierrors.IsNotFound(err) {
klog.Warningf("A pod %v no longer exists", podID)
return
}
klog.Errorf("Error getting pod %v for retry: %v; retrying...", podID, err)
if getBackoff = getBackoff * 2; getBackoff > maximalGetBackoff {
getBackoff = maximalGetBackoff
}
time.Sleep(getBackoff)
}
}()
}
}为什么调度失败需要启动独立的 goroutine 循环 backoff 判断并加入到调度队列中?不是加入一次后调度队列去重试调度就可以了吗?
调度器扩展方式
调度器配置文件:
https://kubernetes.io/docs/reference/config-api/kube-scheduler-config.v1beta2/
Policy & Profile
- Scheduler Policy,用于配置过滤的断言 (Predicates) 和打分的优先级 (Priorities)
- Scheduler Profile,用于配置不同调度阶段的插件
Extender (Webhook 形式)
https://kubernetes.io/docs/reference/config-api/kube-scheduler-policy-config.v1/
community/scheduler_extender.md at master · kubernetes/community
配置文件中的 pilicy 字段下面可以指定 extenders,extender 就是在各个扩展点调用外部的 HTTP 服务
extender 的不足
- 通信成本:需要多一次 HTTP 调用
- 扩展点有限
- 可能有新增节点的需求
- 缓存无法共享
Framework
定义了多个扩展点,每个扩展点可以注册 plugin,使用定义的 interface 用代码实现编译为新的调度器程序,Pod 指定新的调度器名。
扩展点的 plugin 调用顺序如下:
- 扩展点没有配置 plugin:使用默认插件中的扩展
- 扩展点有配置 plugin:先调用默认插件的扩展,再调用配置中的扩展
- 默认插件的扩展始终被最先调用,然后按照
KubeSchedulerConfiguration中扩展的激活enabled顺序逐个调用扩展点的扩展 - 可以先禁用默认插件的扩展,然后在
enabled列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
调度器性能优化
percentageOfNodesToScore 参数,指定多少百分比的节点打分后就足够调度
若不指定,使用一个线性公式:在 100-节点集群取 50%,5000-节点集群取 10%,最低 5%